Premier cluster K8S from scratch sur Debian 12 ⎈


Dans l'optique de passer la formation CKA d'ici la fin de l'année, je me suis lancé dans l'univers Kubernetes ..
Dans ce lab, nous allons voir comment avoir un cluster K8S fonctionnel. Attention je dis fonctionnel, dans un premier temps celui-ci aura des SPOF et ne sera sûrement pas production ready.
Le but étant de prendre en main l'outil et de manipuler les différents composants de K8S (car il y en a et pas qu'un peu..)
Prérequis
- 2 VM pour faire nos nodes/worker K8S ( 3 CPU / 4GB RAM)
- 1 VM pour faire le master/manager (2 CPU / 2 GB RAM)
- 1 loadbalancer (Nous utiliserons celui de notre cloud Provider). Si vous voulez, vous pourrez utiliser une autre VM pour mettre un HAproxy dessus.
Un peu de lexique
Dans K8S, il y a une notion de control plane et de data plane. La control plane est fait pour géré le cluster et la data plane est la partie ou les containers/pods seront exécuté.
Le controle plane est composé des services suivant:
- kube-apiserver -> API pour communiquer avec le cluster
- etcd -> Stockage des clés/valeurs/configuration. Celui-ci doit êtres sauvegarder car il sert à la restauration.
- kube-scheduler -> Prends la décision de l'emplacement des nouveau pod en fonction des ressources/conditions
- kube-controller-manager
- cloud-controller-manager
D'autres services, commande que nous utiliserons:
- kubelet: Un service sur toutes les machines du cluster qui lance le démarrage des pods et communique avec l'api du controle plane.
- kubeadm: Un outil en CLI pour créer et maintenir notre cluster K8S
- kube-proxy: Present sur les worker nodes, permet le transfert des paquets à la bonne destination via IPtables
Préparation des VMs
Avant d'installer les premiers composant K8S, il va falloir faire de la configuration et de l'installation de dépendance sur les 3 nodes (manager/worker).
Désactivation du SWAP
Il n'est pas recommander d'utiliser le swap sur les nodes K8S. Pour le désactiver s'il est actif, il faut:
# Le désactiver temporairement
swapoff -a
# Puis éditer le fichier /etc/fstab et commenter la ligne du swap
Activer le transfert de paquet
Cette fonctionnalité permet de transférer les paquets reçus d'une interface à une autre.
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
# Transfert de paquet
net.ipv4.ip_forward = 1
EOF
# Applique les parametres sans reboot
sudo sysctl --system
Installation d'un CRI
La CRI (Container Runtime Interface), ça permet à Kubelet de communiquer avec la runtime des containers. On a là, le choix entre plusieurs CRI:
- docker
- containerd.io
- CRI-O
On ne va pas faire le tour des différences dans ce lab, mais de ce que j'ai pu lire, la plupart des gens se tournent vers containerd.io c'est donc ce que nous allons faire !
Containerd.io peut être installé de plusieurs façon, j'ai une préférence pour l'installation via apt (cf: https://github.com/containerd/containerd/blob/main/docs/getting-started.md#option-2-from-apt-get-or-dnf)
Le package est disponible dans les repository docker, c'est pourquoi nous allons l'ajouter.
# Mise à jour des repository
sudo apt-get update -y
# Installation des dépendances
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
# Création du dossier pour la clé gpg
sudo install -m 0755 -d /etc/apt/keyrings
# Ajout de la clé gpg docker
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Ajout du repository docker
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Mise à jour des repository (dont le nouveau)
sudo apt-get update -y
# Installation de containerd.io
sudo apt install containerd.io -y
# Activation au démarrage de containerd.io
systemctl enable containerdVérification du driver CGROUP
Normalement de ce côté, nous n'avons rien à toucher, juste faire 2/3 vérifications.
The cgroupfs driver is not recommended when systemd is the init system because systemd expects a single cgroup manager on the system. Additionally, if you use cgroup v2, use the systemd cgroup driver instead of cgroupfs.
-- K8S Official Documentation
Dans notre cas:
- Sur Debian 12 systemd est l'init system.
- Sur Debian 12 nous utilisons du cgroupv2 par défaut.
stat -fc %T /sys/fs/cgroup/
cgroup2fs
Donc il faut utiliser le driver cgroup systemd.
Et autre bonne nouvelle, le driver utilisé par défaut par kubelet est celui-ci. Il faudra uniquement configurer celui-ci sur la CRI.
Starting with v1.22 and later, when creating a cluster with kubeadm, if the user does not set the cgroupDriver field under KubeletConfiguration, kubeadm defaults it to systemd.
-- K8S Official Documentation
Configuration du CRI
Comme l'on a télécharger containerd.io depuis les sources, il va falloir repartir sur une configuration de celui-ci par défaut.
Pour cela, il suffit d'éxecuter la commande suivante.
containerd config default | sudo tee /etc/containerd/config.toml
Suite à ça, il faudra modifier activer le driver systemd Cgroup et modifier l'image de sandbox vers la dernière disponible
/etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
...
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.10"
Vous pouvez aussi lancer les 2 commandes suivantes pour éviter d'éditer le fichier manuellement.
sed 's/SystemdCgroup =.*/SystemdCgroup = true/g' -i /etc/containerd/config.toml
sed 's/sandbox_image =.*/sandbox_image = "registry.k8s.io/pause:3.10"/g' -i /etc/containerd/config.toml
Puis redémarrer containerd pour la prise en compte des modifications
systemctl restart containerd
Installation des outils K8S
Maintenant que tous nos node ont une préconfiguration terminé, nous pouvons installer les outils de K8S. Nous ferrons ceci avec le repository kubernetes.
# Mise à jour des repository
sudo apt-get update -y
# Installation des dépendances
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
# Création du dossier pour la clé gpg
sudo install -m 0755 -d /etc/apt/keyrings
# Ajout de la clé gpg k8s
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# Vérification des permissions
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg
En fonction de la version que l'on souhaite installer, il faut la modifier dans le fichier sourcelist. Actuellement, nous sommes en 1.32.
# Ajout du repository k8s
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.32/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
# Changement des permissions
sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list
Il ne nous reste plus qu'à installer les outils.
# On update le nouveau repository
sudo apt-get update -y
# On installe les outils
sudo apt-get install -y kubectl kubeadm kubelet
# On fixe la version pour éviter les upgrades
sudo apt-mark hold kubelet kubeadm kubectl
# On demarre kubelet et l'active au démarrage
sudo systemctl enable --now kubelet (with now option also start)
Ajout des records DNS
Comme nous n'avons pas de DNS privée de configuré, et qu'il s'agit d'un lab, nous allons directement modifier le fichier /etc/hosts des serveurs afin qu'ils puissent communiquer via leur hostname.
# Le 1er est pour la communication avec les master/manager
# l'utilisation du NS permet d'ajouter d'autre host dans le
# cas d'un passage en HA de etcd sans modifier la configuration K8S.
172.16.4.10 cluster-endpoint
# Chaque hosts
172.16.4.10 inframinds-lab-k8s-manager01
172.16.4.20 inframinds-lab-k8s-node01
172.16.4.21 inframinds-lab-k8s-node02
Initialisation du cluster
C'est parti 🚀 pour la création de notre cluster. Alors les actions suivantes sont à réaliser sur le noeud de management.
# Cela récupérer toutes les images K8S nécessaire pour le fonctionnement du cluster.
kubeadm config images pull
[config/images] Pulled registry.k8s.io/kube-apiserver:v1.28.4
[config/images] Pulled registry.k8s.io/kube-controller-manager:v1.28.4
[config/images] Pulled registry.k8s.io/kube-scheduler:v1.28.4
[config/images] Pulled registry.k8s.io/kube-proxy:v1.28.4
[config/images] Pulled registry.k8s.io/pause:3.10
[config/images] Pulled registry.k8s.io/etcd:3.5.9-0
[config/images] Pulled registry.k8s.io/coredns/coredns:v1.10.1
# Initialisation du leader
kubeadm init --control-plane-endpoint=cluster-endpoint --apiserver-advertise-address=172.16.4.10 --pod-network-cidr=10.244.0.0/16
Alors, voyons les paramètres que nous avons utilisés:
- control-plane-endpoint: C'est le nom de domaine qui sera utilisé pour joindre les managers (API kube / etc)
- apiserver-advertise-address: L'adresse sur laquelle ce node va communiquer (nécessaire si vous avez plusieurs IP)
- pod-network-cidr: Le range que les pods vont utiliser, il faut en choisir 1 pour éviter l'overlaps de réseau. (10.92.0.0/16 est le défaut).
Suite à cette commande, vous allez avoir des instructions pour:
- Rajouter des workers à votre cluster
- Rajouter des managers(control-plane node) à votre cluster
- Communiquer avec votre cluster
Ce qui nous intéresse, sera:
# Ajouter des workers
kubeadm join cluster-endpoint:6443 --token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
# Communiquer avec le cluster
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
Pour ajouter les workers, il vous suffit d'éxecuter la commande généré au-dessus sur vos différents hosts qui ont pour rôles worker.
Une fois que c'est fait, vous pouvez voir l'état de votre cluster.
export KUBECONFIG=/etc/kubernetes/admin.conf
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
inframinds-lab-k8s-manager01 NotReady control-plane 13d v1.32.0 172.16.4.10 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-29-cloud-amd64 containerd://1.7.24
inframinds-lab-k8s-node01 NotReady <none> 13d v1.32.0 172.16.4.20 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-28-cloud-amd64 containerd://1.7.24
inframinds-lab-k8s-node02 NotReady <none> 13d v1.32.0 172.16.4.21 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-26-cloud-amd64 containerd://1.7.25
# More info
kubectl cluster-info
Kubernetes control plane is running at https://cluster-endpoint:6443
CoreDNS is running at https://cluster-endpoint:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Le statut des nodes de votre cluster doit à cet instant être en NotReady, car il manque le composant Network dans le cluster qui empêche CoreDNS de démarrer.
# On liste les pods du namespace kube-system
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5dd5756b68-285ph 0/1 Pending 0 31m
coredns-5dd5756b68-c97hd 0/1 Pending 0 31m
etcd-scw-kube-node01 1/1 Running 0 31m
kube-apiserver-scw-kube-node01 1/1 Running 0 31m
kube-controller-manager-scw-kube-node01 1/1 Running 0 31m
kube-proxy-2njhc 1/1 Running 0 2m33s
kube-proxy-fm8dz 1/1 Running 0 2m45s
kube-proxy-s7krt 1/1 Running 0 31m
kube-scheduler-scw-kube-node01 1/1 Running 0 31m
# On peut regarder les logs des pods qui ne démarre pas
kubectl describe pod coredns-5dd5756b68-285ph -n kube-system
Choix et installation du CNI
Comme on l'a vu dans l'installation de K8S, tous les composants sont libres de choix, il en est de même pour la partie réseau de notre cluster cela s'appelle la CNI (Container Network Interface).
Il en existe énormément, dont les 3 principales sont:
- Cilium
- Calico
- Flannel
Chacun a ses avantages et inconvénients. Par exemple, Cilium utilise eBPF qui permet de s'exécuter à un plus bas niveau qu'iptables et donc qui propose de meilleur performance. Calico et Flannel sont plus "simple".
De ce qu'il en ressort et vu que l'on est là pour apprendre, nous choisirons Cilium.
Comme évoqué dans les avantages, Cilium n'utilise pas iptables pour gérer les flux, on peut donc se séparer du composant kube-proxy (cf: https://docs.cilium.io/en/stable/network/kubernetes/kubeproxy-free/)
# Suppression du Daemonset kube-proxy
kubectl -n kube-system delete ds kube-proxy
# Suppression du configmap pour éviter la réinstallation lors d'un upgrade
kubectl -n kube-system delete cm kube-proxy
# Suppression des chain iptables
iptables-save | grep -v KUBE | iptables-restore
Nous pouvons donc installer Cilium sur notre cluster, pour cela, nous allons installer la CLI sur le manager qui va nous permettre une installation plus simple. (cf: https://docs.cilium.io/en/stable/gettingstarted/k8s-install-default/#install-the-cilium-cli)
CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/main/stable.txt)
CLI_ARCH=amd64
if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi
curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
sha256sum --check cilium-linux-${CLI_ARCH}.tar.gz.sha256sum
sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin
rm cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
Une fois la CLI Cilium installé, nous pouvons déployer notre CNI et vérifier sont statut.
# Installation de la CNI
cilium install --version 1.16.6 --set ipam.operator.clusterPoolIPv4PodCIDRList=10.10.0.0/16 --set ipam.operator.clusterPoolIPv4MaskSize=24
# On attend le setup sur tout les node du cluster
cilium status --wait
Lors de l'installation, il faut là aussi définir le pool d'adressage utilisé par Cilium qui doit être unique.
--set ipam.operator.clusterPoolIPv4PodCIDRList=10.10.0.0/16: permet d'utiliser ce range
--set ipam.operator.clusterPoolIPv4MaskSize=24: c'est la taille du masque par host
Donc ici on aura 10.10.0.0/24 pour le premier host, 10.10.1.0/24 pour le second et etc... Ce range sera utilisé pour donner des IP au pods, on sera donc limité a 255 pods par host.
Vous pouvez voir la configuration courante de Cilium depuis le configmap
kubectl get cm -n kube-system cilium-config -o yaml | grep -i cluster
Une fois tout cela vérifié et configuré, on peut lancer le test de connectivité qui va lancer une centaine de tests et vérifier que tout est OK.
cilium connectivity test
....
✅ [cilium-test-1] All 58 tests (561 actions) successful, 45 tests skipped, 0 scenarios skipped.
Mise en place d'un Ingress Controller
L'ingress Controller est un composant qui joue le rôle de reverse proxy/loadbalancer sur les requêtes entrantes.
La encore, nous avons le choix de notre ingress controller parmi un large panel tel que Nginx / haproxy / traefik / caddy / etc...
Ayant l'habitude de travailler avec Traefik, c'est celui-ci que nous allons utiliser. La mise en place de l'ingress peut se faire de plusieurs manières. Via un helm chart (une sorte de docker compose qui contient tout les objets/services/volume/etc nécessaire pour le fonctionnement de l'ingress) ou via des fichiers YAML qui nous apprendront les différents type d'object et leurs rôles dans K8S. Vous avez deviné, c'est cette dernière méthode que nous allons utiliser.
Attention: Le helm chart de Traefik est sûrement plus quelque chose de production-ready car il respecte les bonnes pratiques (un namespace dédié, l'api Traefik protégé etc). Nous l'exécuterons sûrement à la fin du lab pour avoir une configuration "correcte".
Nous allons donc suivre ce tuto: https://doc.traefik.io/traefik/getting-started/quick-start-with-kubernetes/
Je ne vais pas copier/coller les fichiers yaml, mais simplement essayer d'expliquer ce qu'ils font, et expliquer si l'on doit en modifier, pourquoi.
Le premier fichier est un fichier qui créé un objet de type ClusterRole, celui-ci permet d'avoir accès à plusieurs namespaces, à l'inverse de Role qui se limite au namespace.
# Une liste de permission sur l'api kube
00-role.yml
kubectl apply -f 00-role.yml
kubectl get clusterrole --all-namespaces
Le second fichier est un fichier qui va créer un serviceAccount (un compte de service). Par défaut si aucun service account n'est attacher au pod, alors c'est le service account Default qui l'est.
# La creation d'un user service
00-account
kubectl apply -f 00-account.yml
kubectl get serviceaccount --all-namespaces
Le troisième fichier, permet de faire le lien entre le service account et les permissions. On donne à notre service account la liste de permission crée à l'étape 1.
# Bind des 2 (le user et le role)
01-role-binding.yml
kubectl apply -f 01-role-binding.yml
kubectl get clusterrolebinding --all-namespaces
Maintenant, on passe au déploiement de l'application, il y en a 2 types:
- Deployment: Ou l'on peut jouer sur le nombre de replicat.
- Daemonset: Sur tous les noeuds sauf ce qui ont une "taint" (les master/controle plane par exemple)
Dans leur exemple Traefik utilise le mode Deployment, ça veut dire que si l'on met 3 replicats et que l'on a 10 worker node, seulement 3 des 10 worker node auront un Traefik. L'inverse est aussi vrai, si l'on a 10 replicats et 3 workers node, chaque worker node pourra avoir plusieurs Traefik sur lui.
Cette utilisation est bien si l'on utilise un loadBalancer qui communique avec notre K8S (fournie par les cloud provider ou metalLB). Mais dans notre cas, nous ne pouvons pas l'utiliser. Nous allons donc utiliser le mode DaemonSet qui va permettre d'avoir un pod Traefik sur chacun de nos worker node. Puis dans les étapes suivantes, nous donnerons la liste de nos worker node à notre LB pour qu'il répartisse le trafic entre eux.
Donc pour le fichier 02-traefik.yml nous allons modifier:
# Le kind
kind: Deployment
-> kind: DaemonSet
# supprimer la ligne replica
# Appliquer la conf
kubectl apply -f 02-traefik.yml
L'application est déployée, mais aucun port d'écoute n'est disponible, c'est comme si nous avions lancé un docker sans bind sur un port. Pour cela, les objets de type Service existent, ils permettent l'exposition de port.
Il y a différent type d'exposition:
- LoadBalancer: External LB, qui utilise NodePort de manière dynamique.
- ClusterIP: C'est le défaut, c'est une IP interne au cluster, on peut exposer au public via un ingress (c'est ce que l'on utilisera pour whoiam)
- NodePort: Sur le noeud en dur, en utilisant une IP.
- ExternalName: Aucune idée de ce que ça fait ...
Comme dit plus haut, Traefik dans son tuto utilise le mode LoadBalancer que nous ne pouvons pas utiliser, nous allons donc devoir modifier également le fichier 02-traefik-services.yml
apiVersion: v1
kind: Service
metadata:
name: traefik-dashboard-service
spec:
type: NodePort
ports:
- port: 8080
targetPort: dashboard
nodePort: 30081
selector:
app: traefik
---
apiVersion: v1
kind: Service
metadata:
name: traefik-web-service
spec:
type: NodePort
ports:
- targetPort: web
port: 80
nodePort: 30080
selector:
app: traefik
On utilise le mode NodePort et on fixe les ports qui seront utilisés sur nos hosts. Ici 30080 pour la partie proxy et 30081 pour la partie dashboard d'admin Traefik.
Cela signifie, que sur chacun de nos noeud worker (on est en daemonSet), on aura les ports 30080 et 30081 qui écouteront sur toutes les adresses de nos noeuds.
# Appliquer la conf
kubectl apply -f 02-traefik-services.yml
Comme nous utilisons Cilium et donc eBPF, les ports en écoute ne sont pas visible via les commandes usuelle netstat ou ss. Il faut interroger Cilium pour avoir les mêmes informations.
kubectl -n kube-system exec ds/cilium -- cilium-dbg service list | grep '3008'
Defaulted container "cilium-agent" out of: cilium-agent, config (init), mount-cgroup (init), apply-sysctl-overwrites (init), mount-bpf-fs (init), clean-cilium-state (init), install-cni-binaries (init)
17 172.16.4.20:30080 NodePort 1 => 10.0.2.189:80 (active)
18 0.0.0.0:30080 NodePort 1 => 10.0.2.189:80 (active)
19 <pub_ip_node1>:30080 NodePort 1 => 10.0.2.189:80 (active)
21 172.16.4.20:30081 NodePort 1 => 10.0.2.189:8080 (active)
22 0.0.0.0:30081 NodePort 1 => 10.0.2.189:8080 (active)
23 <pub_ip_node1>:30081 NodePort 1 => 10.0.2.189:8080 (active)
root@inframinds-lab-k8s-manager01:~#
Le fait de passer la commande via le ds/cilium sélectionne 1 des pods Cilium, on a donc les info pour 1 node (ici le node1). Si vous voulez vérifier sur les autres noeuds, il faudra regarder directement avec l'ID des pods.
Déploiement de notre premier service WEB
Notre stack K8S est maintenant fonctionnelle, nous allons donc vérifier cela en déployant un simple service WEB.
Toujours en suivant le tuto de Traefik, nous allons dans un premier temps créer un pod (container)
03-whoami.yml
kubectl apply -f 03-whoami.yml
- Le mode est ici deployment et non daemonset, cela veut dire que nous pourrons choisir le nombre de replicat du pod. (j'en ai mis 4)
- L'image est traefik/whoami par défaut récupéré sur Dockerhub
- Et l'application est disponible sur le port 80
Puis créer le service (exposer le port via un des types d'exposition vu plus haut)
03-whoami-services.yml
kubectl apply -f 03-whoami-services.yml
Ici, il n'y a pas de type défini, alors par défaut, il s'agit d'un type ClusterIP.
À cet instant, notre application whoami est déployer et accessible uniquement depuis l'intérieur de notre cluster K8S. C'est là que l'ingress Controller va entrer en action, il va permettre de router notre requête en fonction de règle sur notre pod.
cat 04-whoami-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: whoami-ingress
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: whoami
port:
number: 80
04-whoami-ingress.yml
kubectl apply -f 04-whoami-ingress.yml
Ici, la règle est simple, tout ce qui arrive sur le / de l'ingress sera redirigé sur le service whoami port 80. En production, des règles par domaine et par path permettront un meilleur routage des requêtes si nous avons plusieurs services.
En faisant un simple curl sur nos 2 workers node, on devrait avoir une réponse
curl 172.16.4.20:30080
Hostname: whoami-68965c9df8-cztmf
IP: 127.0.0.1
IP: ::1
IP: 10.0.1.20
IP: fe80::5c8f:23ff:fec8:5902
RemoteAddr: 10.0.1.25:35666
GET / HTTP/1.1
Host: 172.16.4.20:30080
User-Agent: curl/7.88.1
Accept: */*
Accept-Encoding: gzip
X-Forwarded-For: 10.0.0.227
X-Forwarded-Host: 172.16.4.20:30080
X-Forwarded-Port: 30080
X-Forwarded-Proto: http
X-Forwarded-Server: traefik-deployment-qljvn
X-Real-Ip: 10.0.0.227
root@inframinds-lab-k8s-manager01:~/traefik# curl 172.16.4.21:30080
Hostname: whoami-68965c9df8-cztmf
IP: 127.0.0.1
IP: ::1
IP: 10.0.1.20
IP: fe80::5c8f:23ff:fec8:5902
RemoteAddr: 10.0.1.25:35666
GET / HTTP/1.1
Host: 172.16.4.21:30080
User-Agent: curl/7.88.1
Accept: */*
Accept-Encoding: gzip
X-Forwarded-For: 10.0.0.227
X-Forwarded-Host: 172.16.4.21:30080
X-Forwarded-Port: 30080
X-Forwarded-Proto: http
X-Forwarded-Server: traefik-deployment-qljvn
X-Real-Ip: 10.0.0.227
PS: Même avec 1 seul replicat, les 2 workers node savent l'atteindre.
Afin d'avoir 1 seul point d'entrer publique et une haute disponibilité, il faut ajouter un Loadbalancer devant nos worker nodes sur le port de nos Ingress Controller (30080). Une fois cela fait, vous pourrez joindre votre cluster comme dans le schéma ci-dessous.
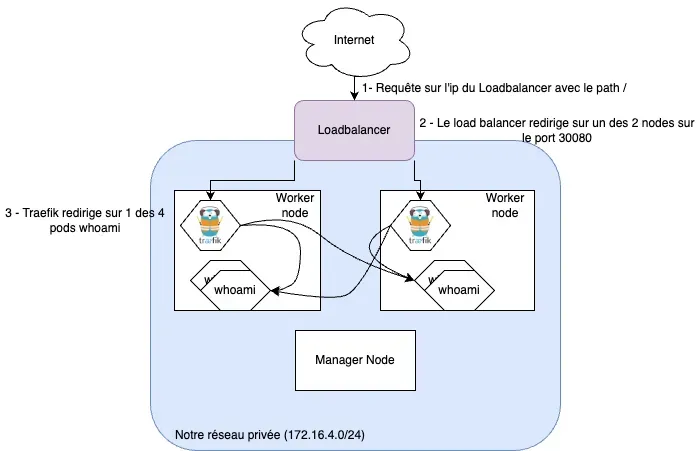
Helm Traefik
Installation de helm
Nous avons suivi la documentation officielle (cf: https://helm.sh/docs/intro/)
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
# On vérifie que le binaire est installé
helm version
Nettoyage de la précédente installation de Traefik
Afin d'avoir un environnement plus propre, nous allons d'abord supprimer tout ce que nous avons fait avec le tuto Traefik
# Dans le dossier avec tous les fichiers .yml de traefik
kubectl delete -f '*.yml'
Installation du chart Traefik
Helm est un gestionnaire de paquet permettant de déployer tous les objets nécessaire au fonctionnement d'une application sur K8S.
On peut configurer un chart helm pour l'adapter à nos besoins via un fichier de variable.
# Ajout du repository traefik contenant le helm chart
helm repo add traefik https://traefik.github.io/charts
helm repo update
# On peut lister les variables avec les valeurs par défaut.
helm show values traefik/traefik
# On créé un namespace dédié pour Traefik
kubectl create ns traefik-ingress
Maintenant, on va modifier/surchargé les valeurs par défaut du chart pour qu'ils conviennent à nos besoins. Pour cela nous créons un fichier traefik-values.yml contenant les modifications suivantes.
deployment:
kind: DaemonSet
service:
type: NodePort
ingressRoute:
dashboard:
enabled: true
ports:
traefik:
nodePort: 30081
expose:
default: true
web:
nodePort: 30080
websecure:
nodePort: 30082
- Le mode DaemonSet
- Le type NodePort
- Les ports sur lesquels on bind.
Une fois ce fichier créé, il suffit d'exécuter la commande suivante pour déployer notre application dans le namespace désiré avec la surcharge des variables.
helm install --namespace=traefik-ingress traefik traefik/traefik --values=./traefik-values.yml
Il est possible de voir l'état du déploiement de notre chart
# Via helm
helm history -n traefik-ingress traefik
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Thu Feb 6 09:59:38 2025 deployed traefik-34.2.0 v3.3.2 Install complete
# Via kubectl
kubectl -n traefik-ingress get all
Maintenant que notre Ingress Controller Traefik est de nouveau opérationnel et de manière plus propre, nous pouvons rajouter comme dans le précédent setup un service web pour vérifier le bon fonctionnement.
Pour cela, on peut soit utiliser les fichiers YAML de Traefik (à partir du 03), soit de faire l'équivalent en ligne de commande.
# équivalent de 03-whoami.yml
kubectl run whoami
# équivalent de 03-whoami-services.yml
kubectl expose pod whoami --port=80 --labels="app=whoami"
# Pour l'ingress on utilisera le fichier 04
kubectl apply -f 04-whoami-ingress.yml
Note: Attention kubectl run met le label "run" au lieu de "app" si on le force pas
Vous devriez avoir maintenant le même fonctionnement qu'avant :)
PS: On peut aussi passer sur un service replicat et l'exposer (il faut utiliser la commande create deployment au lieu de run)
# Suppression du run
kubectl delete pods/whoami
kubectl delete svc/whoami
# Replicat
kubectl create deployment whoami --image=traefik/whoami --port=80 --replicas=3
# Service
kubectl expose deployment whoami --port=80 --labels="app=whoami"
Troubleshooting
Multiple IP sur mes noeuds
Si vous avez plusieurs IP sur vos noeuds, le setup de K8S va par défaut prendre l'IP en lien direct avec votre passerelle par défaut. Si vous souhaitez utiliser une autre IP, il faudra lors de l'installation faire des modifications.
Ajouter le paramètre suivant lors de la commande kube init, en spécifiant l'IP a utiliser.
--apiserver-advertise-address=172.16.4.2
Et modifier la configuration des kubelet (/var/lib/kubelet/kubeadm-flags.env) de tous les noeuds en spécifiant l'IP sur laquelle ils doivent écouter grâce au paramètre suivant:
--node-ip=172.16.4.20
Après cela, il faudra redémarrer le kubelet pour prendre en compte la nouvelle configuration.
L'IP que vous utilisez doit apparaître ici.
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
inframinds-lab-k8s-manager01 Ready control-plane 23d v1.32.0 172.16.4.10 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-29-cloud-amd64 containerd://1.7.24
inframinds-lab-k8s-node01 Ready <none> 23d v1.32.0 172.16.4.20 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-28-cloud-amd64 containerd://1.7.24
inframinds-lab-k8s-node02 Ready <none> 23d v1.32.0 172.16.4.21 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-26-cloud-amd64 containerd://1.7.25
Si vous avez fait les modifications et le redémarrage de kubelet et que ce n'est pas le cas, alors essayer un redémarrage de votre serveur.
Cilium test failed
Si vous avez eu du mal lors du setup du cluster K8S (à cause d'IPtables ou de mauvaise interface, ou autre), il se peut qu'il y ait des logs d'erreur présent dans Cilium qui vous bloque un test.
📋 Test Report [cilium-test-1]
❌ 1/58 tests failed (2/561 actions), 45 tests skipped, 0 scenarios skipped:
Test [check-log-errors]:
❌ check-log-errors/no-errors-in-logs/kubernetes/kube-system/cilium-j6gq7 (cilium-agent)
❌ check-log-errors/no-errors-in-logs/kubernetes/kube-system/cilium-sjjp6 (cilium-agent)
Vous pouvez voir ses logs via les commandes kubectl pour chaque agent Cilium
kubectl logs pod/cilium-sjjp6 -n kube-system
S'il s'agit d'anciens logs qui ne sont plus d'actualité, vous pouvez supprimer le pod pour repartir sur un pod propre et sans erreur afin de finir de passer les tests
kubectl delete pod cilium-sjjp6 -n kube-system
Utilisation d'IPables pour la communication du cluster
Voici le contenu de mon IPtables.
Attention, celui-ci sert uniquement aux services n'utilisant pas eBPF tels que SSH, les communications entre node et master K8S. Pour la partie firewall des pods utilisant Cilium il faudra regarder les policy de Cilium (mais ça sera dans un prochain chapitre).
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [0:0]
# allow loopback network
-A INPUT -i lo -m comment --comment "loopback interface" -j ACCEPT
# Allow ssh pub
-A INPUT -i ens2 -p tcp -m tcp --dport 22 -m comment --comment "Allow all ssh on public" -j ACCEPT
# Allow local subnets
-A INPUT -i ens6 -d 172.16.4.0/22 -m comment --comment "Allow all private subnet" -j ACCEPT
# Allow established
-A INPUT -m conntrack --ctstate ESTABLISHED -m comment --comment "Allow established connections" -j ACCEPT
# Allow cilium to hosts
-A INPUT -s 10.10.0.0/16 -d 172.16.4.0/22 -m comment --comment "Allow cilium host to K8S API" -j ACCEPT
COMMIT